Modèles Vocaux
Vox utilise les modèles Whisper d'OpenAI pour la reconnaissance vocale locale. Ce guide explique les modèles disponibles et comment choisir celui qui correspond à vos besoins.
Comprendre les Modèles Vocaux
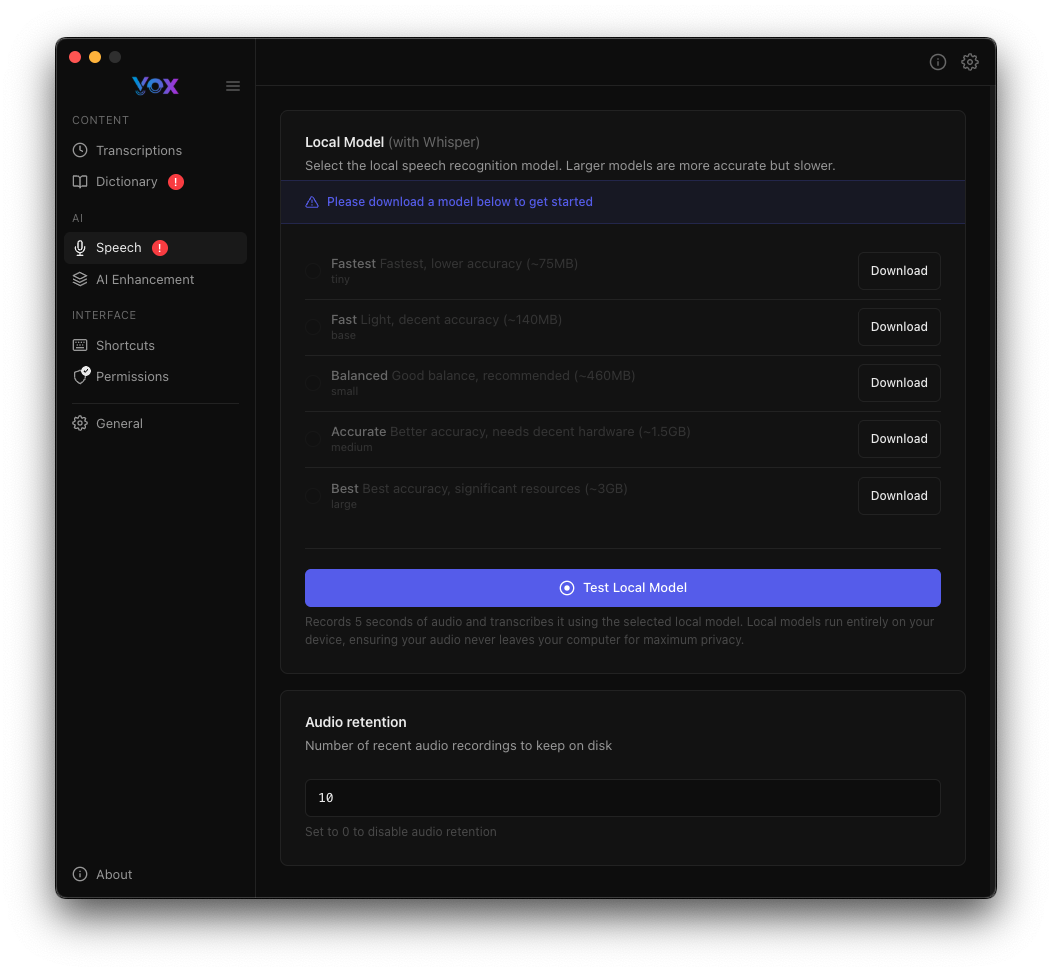
Accédez aux modèles vocaux depuis Paramètres → Voix.
Qu'est-ce que les Modèles Whisper ?
Whisper est le système de reconnaissance automatique de la parole (ASR) open-source d'OpenAI. Vox exécute ces modèles localement sur votre appareil, garantissant :
- Confidentialité : L'audio ne quitte jamais votre appareil
- Capacité hors ligne : Fonctionne sans connexion internet
- Rapidité : Pas de latence réseau
- Coût : Pas de frais à la minute
Confidentialité en Premier
Toute la reconnaissance vocale se produit sur votre appareil. Vos données vocales ne sont jamais envoyées à des serveurs externes (sauf si vous activez l'Amélioration par IA).
Modèles Disponibles
Vox propose cinq variantes du modèle Whisper, chacune équilibrant différemment vitesse et précision :
Le Plus Rapide
Taille : ~75MB Vitesse : Latence minimale (<50ms) Précision : Bonne pour une parole claire Idéal pour : Commandes rapides, phrases courtes, tests
Le modèle le plus petit et le plus rapide. Idéal pour les utilisateurs qui privilégient la vitesse à la précision ou disposent d'un espace disque limité.
Rapide
Taille : ~150MB Vitesse : Très faible latence (~50ms) Précision : Meilleure que Le Plus Rapide Idéal pour : Usage quotidien avec une parole claire
Un bon compromis entre vitesse et qualité. Convient à la plupart des besoins de transcription occasionnelle.
Équilibré
Taille : ~480MB Vitesse : Recommandé (~480MB) Précision : Bonne précision polyvalente Idéal pour : La plupart des utilisateurs, transcription générale
Recommandé pour la plupart des utilisateurs. Fournit une excellente précision pour un usage quotidien sans nécessiter de ressources excessives.
Précis
Taille : ~1,5GB Vitesse : Meilleure précision, latence plus correcte (~1,5GB) Précision : Haute précision pour une parole complexe Idéal pour : Transcription professionnelle, contenu technique, accents
Précision supérieure pour des conditions audio difficiles, la terminologie technique et divers accents.
Meilleur
Taille : ~3GB Vitesse : Qualité maximale, CPU significatif (~3GB) Précision : Précision maximale Idéal pour : Transcription critique, multilingue, environnements bruyants
Le modèle le plus grand et le plus précis. À utiliser lorsque la qualité de transcription est primordiale et que les ressources système le permettent.
Télécharger les Modèles
Configuration Initiale
Lorsque vous installez Vox pour la première fois, aucun modèle n'est téléchargé. Vous devez télécharger au moins un modèle pour utiliser Vox.
Pour télécharger un modèle :
- Accédez à Paramètres → Voix
- Cliquez sur Télécharger à côté du modèle choisi
- Attendez que le téléchargement se termine
- Le bouton devient "Téléchargé" lorsqu'il est prêt
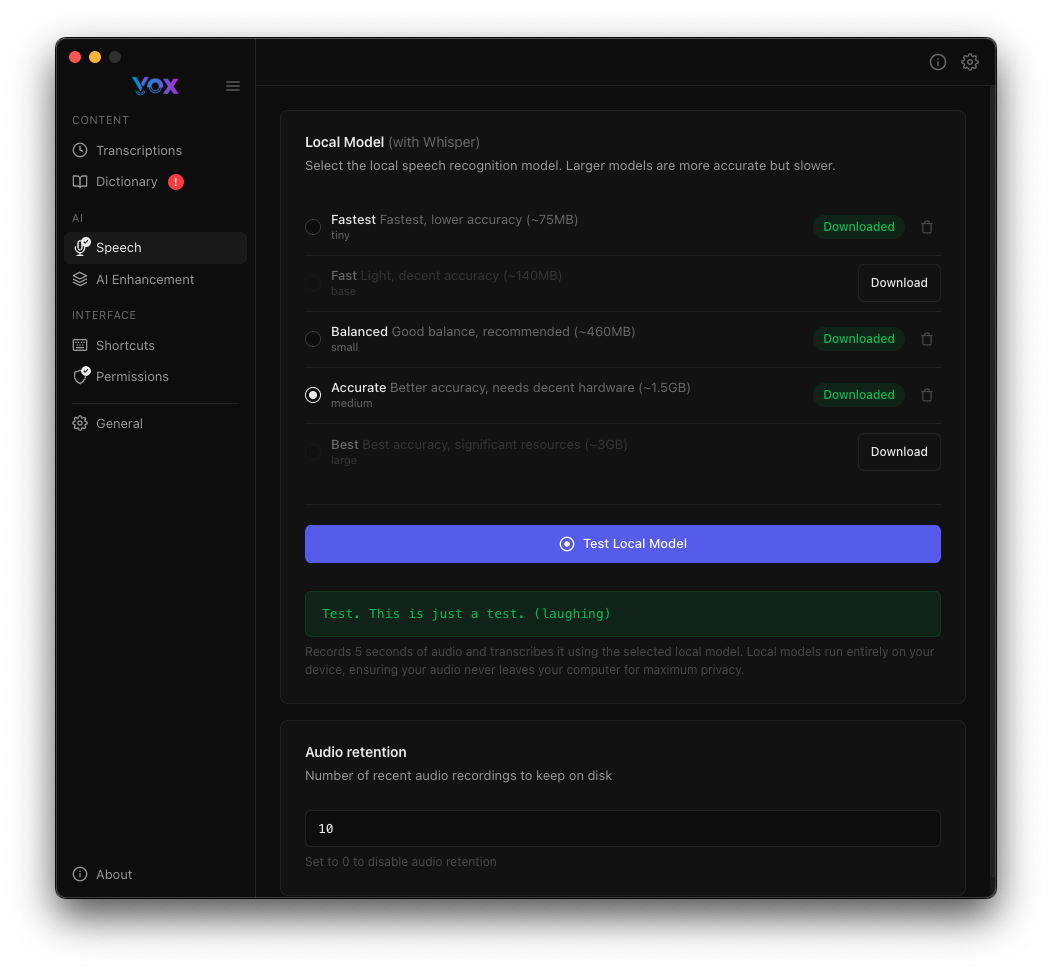
Recommandation Premier Modèle
Commencez avec Équilibré pour le meilleur équilibre entre qualité et performance. Vous pouvez toujours télécharger des modèles supplémentaires plus tard.
Télécharger Plusieurs Modèles
Vous pouvez télécharger plusieurs modèles et basculer entre eux :
- Téléchargez différents modèles pour différents cas d'usage
- Testez chaque modèle avec le bouton Tester le Modèle Local
- Vox utilise le modèle actuellement sélectionné (marqué d'une coche)
- Basculez entre les modèles à tout moment sans re-télécharger
Exigences de Téléchargement
- Connexion internet : Requise pour le téléchargement initial
- Espace disque : Assurez-vous d'avoir suffisamment d'espace pour le modèle choisi
- Temps : Les téléchargements prennent généralement 1 à 10 minutes selon la taille du modèle et la vitesse de connexion
Configuration Requise
Vox a différentes configurations requises selon votre système d'exploitation :
macOS
| Exigence | Minimum | Recommandé |
|---|---|---|
| Version du SE | macOS 15 (Sequoia) | macOS 15+ (Sequoia ou ultérieur) |
| Processeur | Apple Silicon (M1) ou Intel | Apple Silicon (M2 ou plus récent) |
| RAM | 4 Go | 8 Go ou plus |
| Stockage | 500 Mo - 4 Go | 4 Go d'espace libre |
| Permissions | Microphone + Accessibilité | - |
Performance sur Apple Silicon
Vox fonctionne beaucoup plus rapidement sur Apple Silicon (M1/M2/M3) par rapport aux Macs Intel grâce à un support optimisé du moteur neuronal.
Windows
| Exigence | Minimum | Recommandé |
|---|---|---|
| Version du SE | Windows 10 (64-bit) | Windows 11 |
| Processeur | Processeur x64 | Processeur multicœur moderne |
| RAM | 4 Go | 8 Go ou plus |
| Stockage | 500 Mo - 4 Go | 4 Go d'espace libre |
| Permissions | Accès au microphone | - |
Performance sous Windows
Les performances varient selon le processeur. Les processeurs modernes (Intel 10e gen+, AMD Ryzen 3000+) offrent une meilleure vitesse de transcription.
Bientôt Disponible
Le support pour Linux, iOS et Android est prévu pour les versions futures. Voir la feuille de route →
Tester les Modèles
Après avoir téléchargé un modèle, vérifiez qu'il fonctionne correctement :
- Cliquez sur Tester le Modèle Local
- Dites une phrase de test lorsque vous y êtes invité
- Examinez le résultat de la transcription
- Cherchez le message de succès : "Yeah. This is just a test. I laughing"
Le test vérifie :
- Le modèle est correctement téléchargé et installé
- Le pipeline audio fonctionne
- La précision de la transcription répond à vos besoins
Testez avec du Contenu Réel
Testez avec des phrases similaires à votre cas d'usage réel (termes techniques, noms, etc.) pour évaluer la précision.
Choisir le Bon Modèle
Matrice de Décision
| Modèle | Taille | Vitesse | Précision | Idéal Pour |
|---|---|---|---|---|
| Le Plus Rapide | 75MB | ⚡⚡⚡⚡⚡ | ⭐⭐⭐ | Tests, commandes simples |
| Rapide | 150MB | ⚡⚡⚡⚡ | ⭐⭐⭐⭐ | Usage quotidien, parole claire |
| Équilibré | 480MB | ⚡⚡⚡ | ⭐⭐⭐⭐ | Recommandé pour la plupart |
| Précis | 1,5GB | ⚡⚡ | ⭐⭐⭐⭐⭐ | Travail professionnel, contenu technique |
| Meilleur | 3GB | ⚡ | ⭐⭐⭐⭐⭐ | Transcription critique, audio complexe |
Considérez Votre Cas d'Usage
Choisissez Le Plus Rapide ou Rapide si vous :
- Avez besoin de résultats de transcription instantanés
- Transcrivez des phrases courtes et simples
- Avez un espace disque limité
- Parlez clairement dans des environnements calmes
Choisissez Équilibré si vous :
- Voulez une bonne expérience globale
- Transcrivez du contenu court et long
- Avez besoin d'une précision fiable sans trop sacrifier la vitesse
- N'êtes pas sûr quel modèle choisir (commencez ici !)
Choisissez Précis si vous :
- Travaillez avec de la terminologie technique
- Parlez avec un accent ou en plusieurs langues
- Transcrivez dans des environnements avec du bruit de fond
- Avez besoin d'une haute précision pour un travail professionnel
Choisissez Meilleur si vous :
- Nécessitez une précision de transcription maximale
- Travaillez avec du contenu complexe et multilingue
- Transcrivez des documents critiques ou du contenu juridique
- Avez un ordinateur puissant avec beaucoup de ressources
Configuration Système Requise
Tous les modèles fonctionnent sur tout ordinateur qui exécute Vox, mais les performances varient :
Pour Le Plus Rapide, Rapide, Équilibré :
- Tout Mac de 2018 ou ultérieur / Tout PC Windows moderne
- 8Go de RAM minimum
- Performances standard attendues
Pour Précis :
- Mac de 2020 ou ultérieur / PC Windows avec 8 Go+ de RAM recommandé
- 16Go de RAM recommandé
- Peut être plus lent sur les ordinateurs anciens
Pour Meilleur :
- Mac Apple Silicon ou PC Windows moderne avec 16 Go+ de RAM
- 16Go+ de RAM recommandé
- Attendez un temps de traitement notable sur les transcriptions
Avantage Apple Silicon
Les Macs avec Apple Silicon (puces M1, M2, M3) exécutent les modèles Whisper significativement plus vite que les Macs Intel grâce à leur Neural Engine.
Performance des Modèles
Exemples de Temps de Traitement
Temps de transcription approximatifs pour un enregistrement de 10 secondes :
| Modèle | Intel Mac (2019) | M1/M2 Mac | M3 Mac |
|---|---|---|---|
| Le Plus Rapide | 0,5s | 0,2s | 0,1s |
| Rapide | 1s | 0,5s | 0,3s |
| Équilibré | 2s | 1s | 0,5s |
| Précis | 5s | 2,5s | 1,5s |
| Meilleur | 10s | 4s | 2s |
Les temps sont approximatifs et varient selon la complexité audio
Les performances sur des PC Windows avec des spécifications équivalentes sont comparables.
Comparaison de Précision
Exemple de qualité de transcription avec des termes techniques :
Parole originale : "Initialize the TypeScript interface with async await handlers"
| Modèle | Qualité de Transcription |
|---|---|
| Le Plus Rapide | "Initialize the typescript interface with a sync away handlers" |
| Rapide | "Initialize the TypeScript interface with a sync await handlers" |
| Équilibré | "Initialize the TypeScript interface with async await handlers" ✓ |
| Précis | "Initialize the TypeScript interface with async await handlers" ✓ |
| Meilleur | "Initialize the TypeScript interface with async await handlers" ✓ |
Amélioration par IA
Pour une précision encore meilleure, activez l'Amélioration par IA pour post-traiter les transcriptions avec des grands modèles de langage.
Rétention Audio
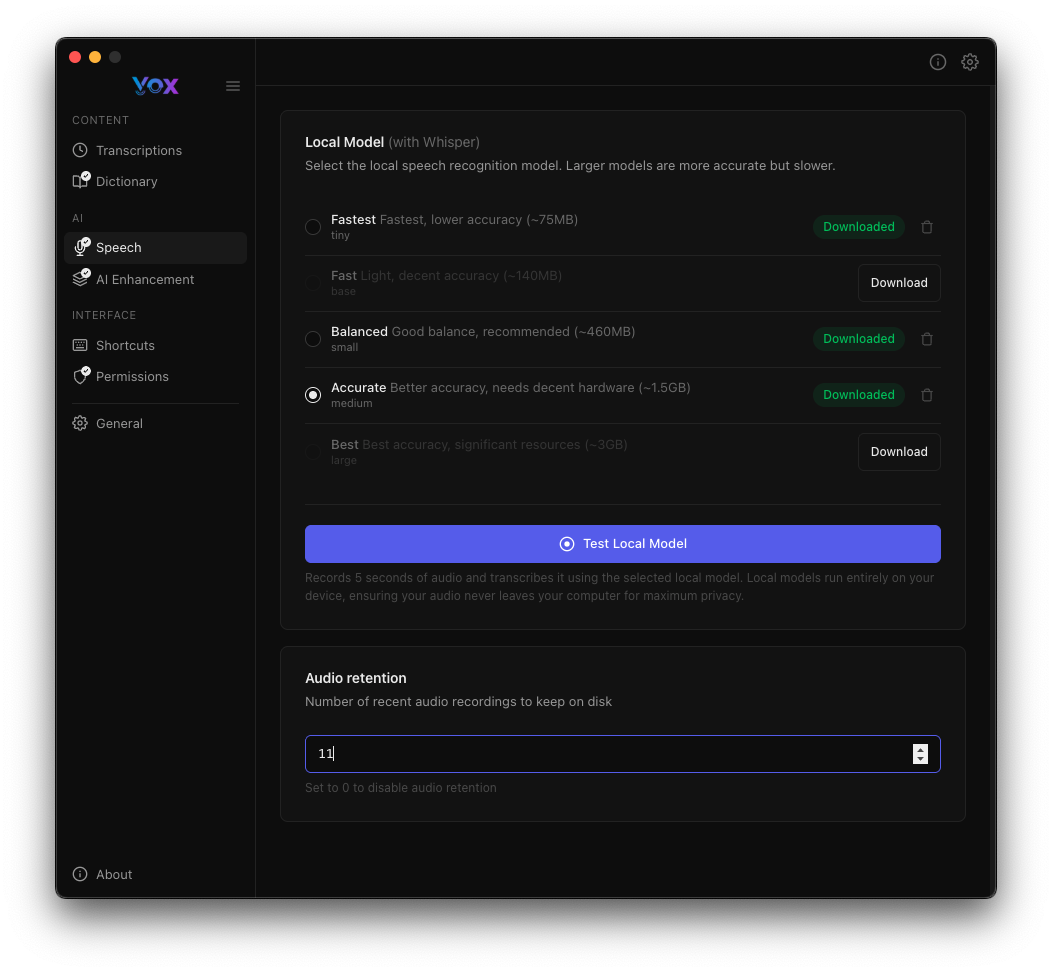
Configurez combien d'enregistrements audio récents Vox conserve sur disque :
Par défaut : 10 enregistrements
Pourquoi conserver l'audio :
- Réviser les transcriptions pour vérifier la précision
- Tester différents modèles sur le même audio
- Ajouter des mots manqués à votre dictionnaire
- Déboguer les problèmes de transcription
Ajuster la rétention :
- Augmenter si vous révisez fréquemment les enregistrements passés
- Diminuer pour économiser de l'espace disque
- Définir à
0pour désactiver entièrement la rétention audio
Note sur la Confidentialité
Les enregistrements audio sont stockés localement dans le dossier de l'application Vox. Ils ne sont jamais envoyés sauf si vous activez explicitement les fonctionnalités d'Amélioration par IA.
Changer de Modèle
Vous pouvez changer quel modèle Vox utilise à tout moment :
- Accédez à Paramètres → Voix
- Cliquez sur un autre modèle téléchargé
- Le modèle avec une coche est actif
- Votre prochain enregistrement utilisera le nouveau modèle
Pas de redémarrage nécessaire - le changement prend effet immédiatement.
Gérer l'Espace Disque
Vérifier le Stockage des Modèles
Les modèles sont stockés dans :
~/Library/Application Support/Vox/models/Supprimer des Modèles
Pour libérer de l'espace disque :
- Accédez à Paramètres → Voix
- Trouvez les modèles dont vous n'avez plus besoin
- Cliquez sur l'icône corbeille à côté du modèle
- Confirmez la suppression
Vous pouvez re-télécharger les modèles à tout moment sans pénalité.
Conseils de Stockage
- Gardez seulement les modèles que vous utilisez activement
- Le modèle Équilibré est un bon choix de modèle unique
- Téléchargez des modèles plus grands seulement quand nécessaire
- La rétention audio prend un espace minimal (configurable)
Dépannage
Téléchargement du Modèle Échoué
Solution :
- Vérifiez votre connexion internet
- Assurez-vous d'avoir suffisamment d'espace disque
- Essayez de télécharger un modèle plus petit d'abord
- Redémarrez Vox et réessayez
Le Test du Modèle Local Échoue
Solution :
- Vérifiez que l'autorisation microphone est accordée
- Vérifiez Préférences Système → Son → Entrée pour la sélection du microphone
- Essayez un modèle différent
- Redémarrez Vox
Mauvaise Qualité de Transcription
Solutions :
- Passer à un modèle plus grand : Essayez Précis ou Meilleur
- Vérifier la qualité audio : Parlez clairement, réduisez le bruit de fond
- Ajouter des mots personnalisés : Utilisez la fonction Dictionnaire
- Activer l'Amélioration par IA : Post-traitez avec IA pour de meilleurs résultats
Le Modèle Prend Trop Longtemps à Traiter
Solutions :
- Passer à un modèle plus petit : Essayez Rapide ou Équilibré
- Raccourcir les enregistrements : Divisez les longues dictées en morceaux plus petits
- Fermer d'autres applications : Libérez des ressources CPU
- Vérifier l'activité système : Assurez-vous que votre ordinateur n'est pas sous forte charge
Modèle Utilisant Trop de CPU/Mémoire
Solutions :
- Passez à un modèle plus petit (Le Plus Rapide ou Rapide)
- Fermez les applications en arrière-plan
- Réduisez la rétention audio pour libérer des ressources
- Envisagez de mettre à niveau votre matériel si vous avez besoin de modèles plus grands
Sujets Avancés
Architecture des Modèles
Vox utilise des versions quantifiées des modèles Whisper optimisées pour :
- Inférence optimisée sur toutes les plateformes
- Une empreinte mémoire réduite
- Une précision maintenue par rapport aux modèles originaux
- L'accélération du Neural Engine d'Apple Silicon
Support des Langues
Tous les modèles Whisper prennent en charge plusieurs langues dont :
- Anglais, Espagnol, Français, Allemand, Italien, Portugais
- Chinois, Japonais, Coréen
- Et 90+ autres langues
Configurez les langues de parole dans Paramètres → Général → Langues.
Modèles Personnalisés
Actuellement, Vox ne prend en charge que les cinq variantes Whisper intégrées. Le support de modèles personnalisés pourrait être ajouté dans les versions futures.
Prochaines Étapes
- Activer l'Amélioration par IA pour une meilleure qualité de transcription
- Ajouter des mots personnalisés pour améliorer la précision des termes techniques
- Configurer les raccourcis pour un enregistrement facile
- Ajuster les paramètres HUD pour un meilleur retour d'enregistrement