Modelos de Fala
O Vox usa os modelos Whisper da OpenAI para reconhecimento de fala local. Este guia explica os modelos disponíveis e como escolher o certo para suas necessidades.
Compreendendo os Modelos de Fala
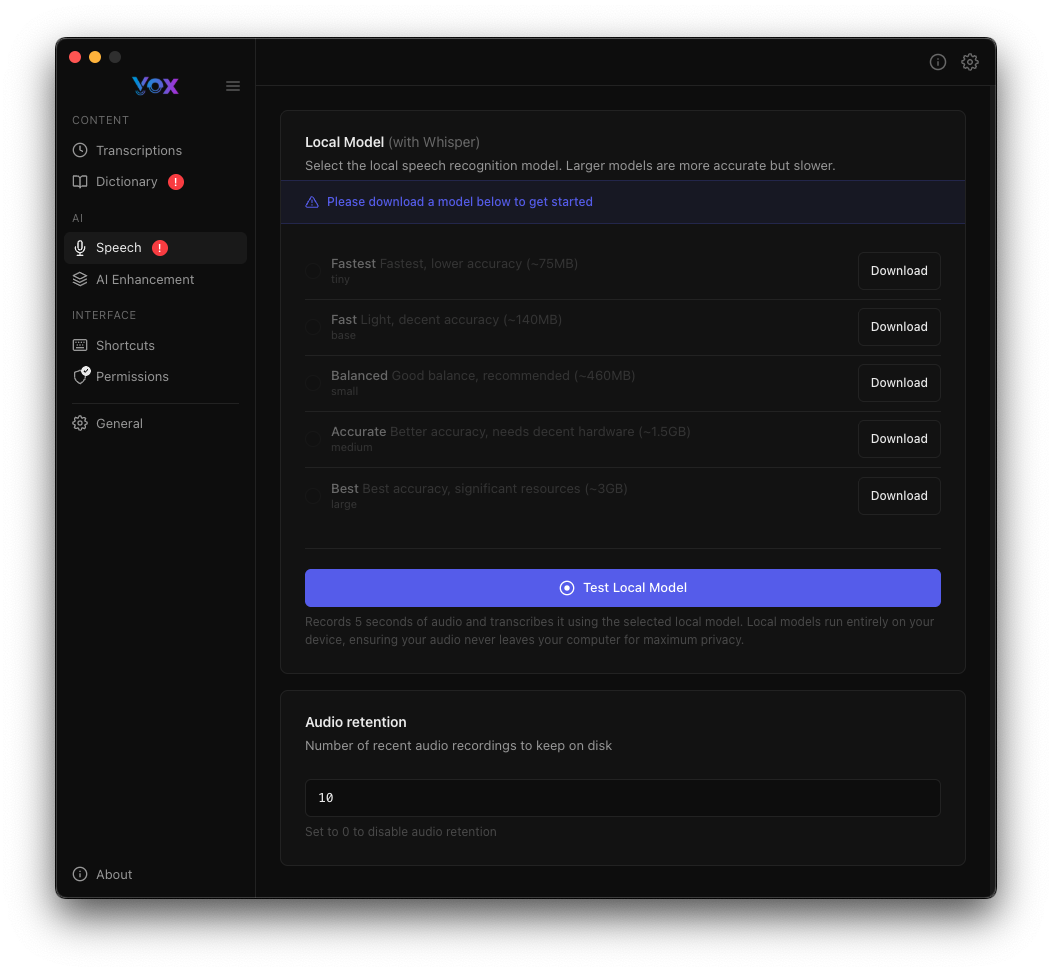
Acesse os modelos de fala em Configurações → Fala.
O Que São Modelos Whisper?
Whisper é o sistema de reconhecimento automático de fala (ASR) de código aberto da OpenAI. O Vox executa esses modelos localmente no seu dispositivo, garantindo:
- Privacidade: O áudio nunca sai do seu dispositivo
- Capacidade offline: Funciona sem conexão à internet
- Velocidade: Sem latência de rede
- Custo: Sem cobranças por minuto
Privacidade em Primeiro Lugar
Todo o reconhecimento de fala acontece no seu dispositivo. Seus dados de voz nunca são enviados a servidores externos (a menos que você ative o Aprimoramento por IA).
Modelos Disponíveis
O Vox oferece cinco variantes do modelo Whisper, cada uma equilibrando velocidade e precisão de forma diferente:
Mais Rápido
Tamanho: ~75MB Velocidade: Menor latência (<50ms) Precisão: Boa para fala clara Melhor para: Comandos rápidos, frases curtas, testes
O menor e mais rápido modelo. Ideal para usuários que priorizam velocidade sobre precisão ou têm espaço em disco limitado.
Rápido
Tamanho: ~150MB Velocidade: Latência muito baixa (~50ms) Precisão: Melhor que Mais Rápido Melhor para: Uso diário com fala clara
Um bom meio-termo entre velocidade e qualidade. Adequado para a maioria das necessidades de transcrição casual.
Equilibrado
Tamanho: ~480MB Velocidade: Recomendado (~480MB) Precisão: Boa precisão para uso geral Melhor para: A maioria dos usuários, transcrição geral
Recomendado para a maioria dos usuários. Fornece excelente precisão para uso diário sem exigir recursos excessivos.
Preciso
Tamanho: ~1,5GB Velocidade: Melhor precisão, latência mais decente (~1,5GB) Precisão: Alta precisão para fala complexa Melhor para: Transcrição profissional, conteúdo técnico, sotaques
Maior precisão para condições de áudio desafiadoras, terminologia técnica e vários sotaques.
Melhor
Tamanho: ~3GB Velocidade: Maior qualidade, CPU significativo (~3GB) Precisão: Precisão máxima Melhor para: Transcrição crítica, multilíngue, ambientes ruidosos
O maior e mais preciso modelo. Use quando a qualidade da transcrição é fundamental e os recursos do sistema permitem.
Baixando Modelos
Configuração Inicial
Quando você instala o Vox pela primeira vez, nenhum modelo está baixado. Você deve baixar pelo menos um modelo para usar o Vox.
Para baixar um modelo:
- Navegue até Configurações → Fala
- Clique em Baixar ao lado do modelo escolhido
- Aguarde o download ser concluído
- O botão muda para "Baixado" quando estiver pronto
Recomendação de Primeiro Modelo
Comece com Equilibrado para o melhor equilíbrio entre qualidade e desempenho. Você sempre pode baixar modelos adicionais depois.
Baixando Vários Modelos
Você pode baixar vários modelos e alternar entre eles:
- Baixe modelos diferentes para casos de uso diferentes
- Teste cada modelo com o botão Testar Modelo Local
- O Vox usa o modelo atualmente selecionado (marcado com uma marca de seleção)
- Alterne entre modelos a qualquer momento sem precisar baixar novamente
Requisitos de Download
- Conexão à internet: Necessária para download inicial
- Espaço em disco: Certifique-se de ter espaço suficiente para o modelo escolhido
- Tempo: Os downloads geralmente levam de 1 a 10 minutos dependendo do tamanho do modelo e velocidade de conexão
Requisitos do Sistema
O Vox tem requisitos de sistema diferentes dependendo do seu sistema operacional:
macOS
| Requisito | Mínimo | Recomendado |
|---|---|---|
| Versão do SO | macOS 15 (Sequoia) | macOS 15+ (Sequoia ou posterior) |
| Processador | Apple Silicon (M1) ou Intel | Apple Silicon (M2 ou mais recente) |
| RAM | 4 GB | 8 GB ou mais |
| Armazenamento | 500 MB - 4 GB | 4 GB de espaço livre |
| Permissões | Microfone + Acessibilidade | - |
Desempenho no Apple Silicon
O Vox roda significativamente mais rápido no Apple Silicon (M1/M2/M3) comparado aos Macs Intel devido ao suporte otimizado do neural engine.
Windows
| Requisito | Mínimo | Recomendado |
|---|---|---|
| Versão do SO | Windows 10 (64-bit) | Windows 11 |
| Processador | Processador x64 | Processador multi-core moderno |
| RAM | 4 GB | 8 GB ou mais |
| Armazenamento | 500 MB - 4 GB | 4 GB de espaço livre |
| Permissões | Acesso ao microfone | - |
Desempenho no Windows
O desempenho varia baseado no processador. CPUs modernas (Intel 10ª geração+, AMD Ryzen 3000+) oferecem melhor velocidade de transcrição.
Em Breve
Suporte para Linux, iOS e Android está planejado para versões futuras. Ver roadmap →
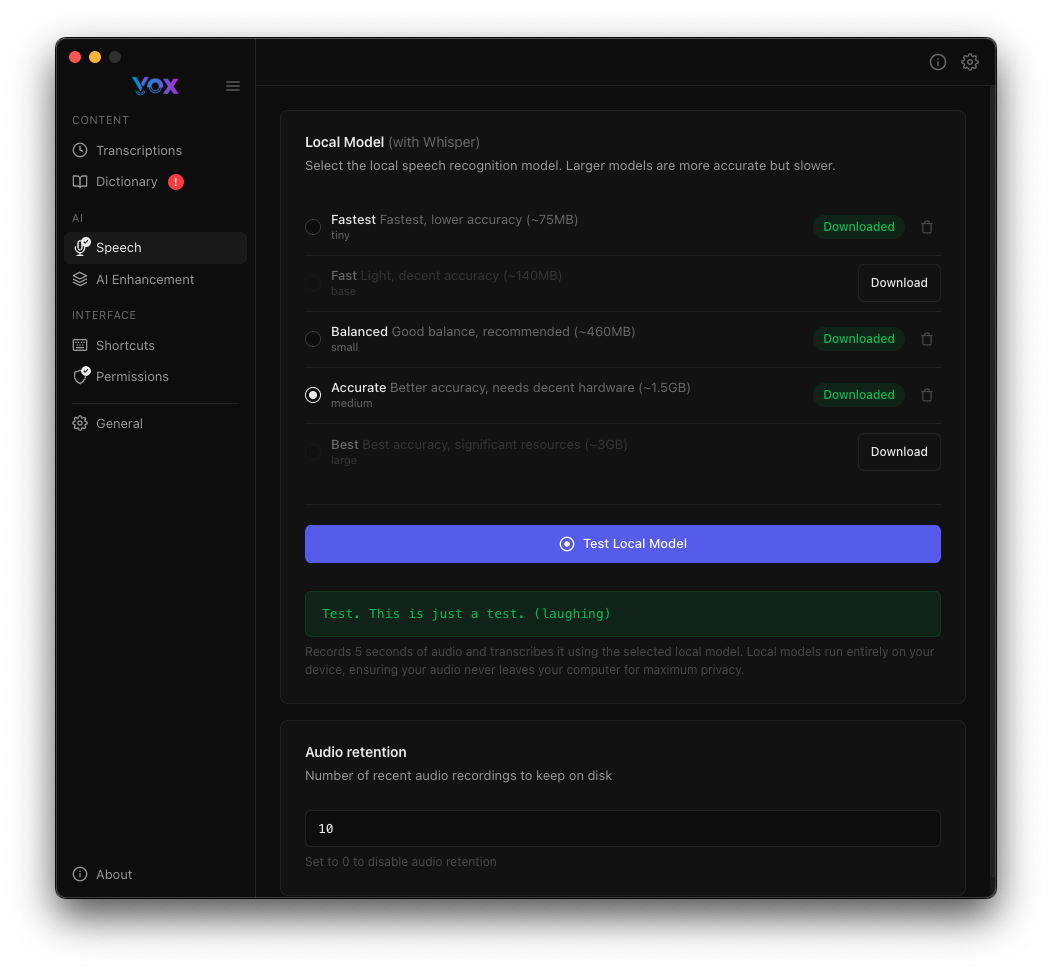
Testando Modelos
Após baixar um modelo, verifique se funciona corretamente:
- Clique em Testar Modelo Local
- Fale uma frase de teste quando solicitado
- Revise o resultado da transcrição
- Procure pela mensagem de sucesso: "Yeah. This is just a test. I laughing"
O teste verifica:
- O modelo está devidamente baixado e instalado
- O pipeline de áudio está funcionando
- A precisão da transcrição atende às suas necessidades
Teste com Conteúdo Real
Teste com frases similares ao seu caso de uso real (termos técnicos, nomes, etc.) para avaliar a precisão.
Escolhendo o Modelo Certo
Matriz de Decisão
| Modelo | Tamanho | Velocidade | Precisão | Melhor Para |
|---|---|---|---|---|
| Mais Rápido | 75MB | ⚡⚡⚡⚡⚡ | ⭐⭐⭐ | Testes, comandos simples |
| Rápido | 150MB | ⚡⚡⚡⚡ | ⭐⭐⭐⭐ | Uso diário, fala clara |
| Equilibrado | 480MB | ⚡⚡⚡ | ⭐⭐⭐⭐ | Recomendado para a maioria |
| Preciso | 1,5GB | ⚡⚡ | ⭐⭐⭐⭐⭐ | Trabalho profissional, conteúdo técnico |
| Melhor | 3GB | ⚡ | ⭐⭐⭐⭐⭐ | Transcrição crítica, áudio complexo |
Considere seu Caso de Uso
Escolha Mais Rápido ou Rápido se você:
- Precisa de resultados de transcrição instantâneos
- Transcreve frases curtas e simples
- Tem espaço em disco limitado
- Fala claramente em ambientes silenciosos
Escolha Equilibrado se você:
- Quer uma boa experiência geral
- Transcreve conteúdo tanto curto quanto longo
- Precisa de precisão confiável sem sacrificar muito a velocidade
- Não tem certeza qual modelo escolher (comece aqui!)
Escolha Preciso se você:
- Trabalha com terminologia técnica
- Fala com sotaque ou em vários idiomas
- Transcreve em ambientes com ruído de fundo
- Precisa de alta precisão para trabalho profissional
Escolha Melhor se você:
- Precisa de precisão máxima de transcrição
- Trabalha com conteúdo complexo e multilíngue
- Transcreve documentos críticos ou conteúdo jurídico
- Tem um computador potente com bastante recursos
Requisitos de Desempenho do Modelo
Todos os modelos funcionam em qualquer computador que executa o Vox, mas o desempenho varia:
Para Mais Rápido, Rápido, Equilibrado:
- Qualquer Mac de 2018 ou posterior / Qualquer PC Windows moderno
- 8GB de RAM mínimo
- Expectativas de desempenho padrão
Para Preciso:
- Mac de 2020 ou posterior / PC Windows com 8GB+ de RAM recomendado
- 16GB de RAM recomendado
- Pode ser mais lento em hardware mais antigo
Para Melhor:
- Mac com Apple Silicon ou PC Windows moderno com 16GB+ de RAM
- 16GB+ de RAM recomendado
- Espere tempo de processamento notável nas transcrições
Vantagem do Apple Silicon
Macs com Apple Silicon (chips M1, M2, M3) executam modelos Whisper significativamente mais rápido que Macs Intel devido ao seu Neural Engine.
Desempenho dos Modelos
Exemplos de Tempo de Processamento
Tempos aproximados de transcrição para uma gravação de 10 segundos:
O desempenho em PCs Windows com especificações equivalentes é comparável.
| Modelo | Intel Mac (2019) | M1/M2 Mac | M3 Mac |
|---|---|---|---|
| Mais Rápido | 0,5s | 0,2s | 0,1s |
| Rápido | 1s | 0,5s | 0,3s |
| Equilibrado | 2s | 1s | 0,5s |
| Preciso | 5s | 2,5s | 1,5s |
| Melhor | 10s | 4s | 2s |
Os tempos são aproximados e variam com base na complexidade do áudio
Comparação de Precisão
Exemplo de qualidade de transcrição com termos técnicos:
Fala original: "Initialize the TypeScript interface with async await handlers"
| Modelo | Qualidade da Transcrição |
|---|---|
| Mais Rápido | "Initialize the typescript interface with a sync away handlers" |
| Rápido | "Initialize the TypeScript interface with a sync await handlers" |
| Equilibrado | "Initialize the TypeScript interface with async await handlers" ✓ |
| Preciso | "Initialize the TypeScript interface with async await handlers" ✓ |
| Melhor | "Initialize the TypeScript interface with async await handlers" ✓ |
Aprimoramento por IA
Para precisão ainda melhor, ative o Aprimoramento por IA para pós-processar transcrições com modelos de linguagem grandes.
Retenção de Áudio
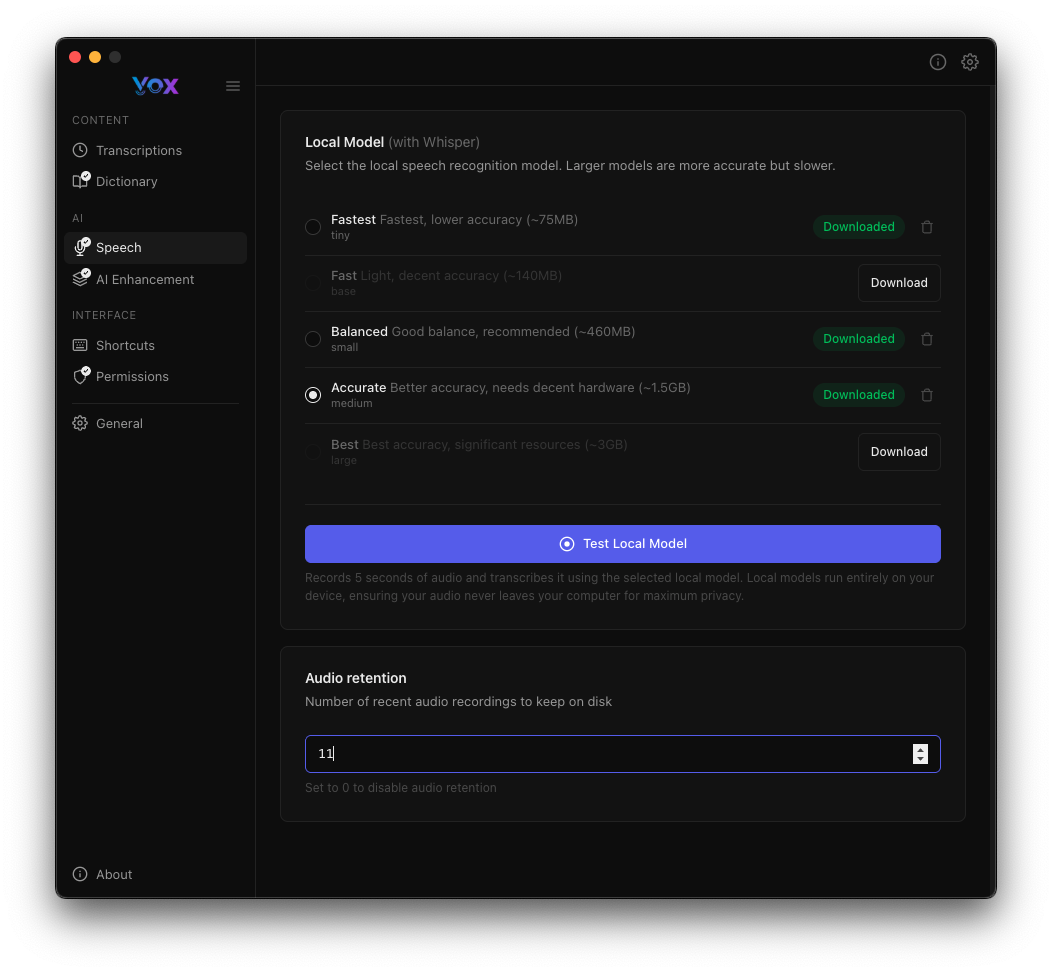
Configure quantas gravações de áudio recentes o Vox mantém em disco:
Padrão: 10 gravações
Por que manter áudio:
- Revisar transcrições para verificar precisão
- Testar modelos diferentes no mesmo áudio
- Adicionar palavras perdidas ao seu dicionário
- Depurar problemas de transcrição
Ajustar retenção:
- Aumentar se você frequentemente revisita gravações passadas
- Diminuir para economizar espaço em disco
- Defina como
0para desativar a retenção de áudio completamente
Nota de Privacidade
As gravações de áudio são armazenadas localmente na pasta do aplicativo Vox. Elas nunca são enviadas, a menos que você ative explicitamente os recursos de Aprimoramento por IA.
Alternando Modelos
Você pode alterar qual modelo o Vox usa a qualquer momento:
- Navegue até Configurações → Fala
- Clique em um modelo baixado diferente
- O modelo com uma marca de seleção está ativo
- Sua próxima gravação usará o novo modelo
Não é necessário reiniciar - a alteração entra em vigor imediatamente.
Gerenciando Espaço em Disco
Verificando o Armazenamento do Modelo
Os modelos são armazenados em:
~/Library/Application Support/Vox/models/Removendo Modelos
Para liberar espaço em disco:
- Navegue até Configurações → Fala
- Encontre modelos que você não precisa mais
- Clique no ícone de lixeira ao lado do modelo
- Confirme a exclusão
Você pode baixar novamente os modelos a qualquer momento sem penalidade.
Dicas de Armazenamento
- Mantenha apenas os modelos que você usa ativamente
- O modelo Equilibrado é uma boa escolha de modelo único
- Baixe modelos maiores apenas quando necessário
- A retenção de áudio ocupa espaço mínimo (configurável)
Solução de Problemas
Download do Modelo Falhou
Solução:
- Verifique sua conexão à internet
- Certifique-se de ter espaço em disco suficiente
- Tente baixar um modelo menor primeiro
- Reinicie o Vox e tente novamente
Teste do Modelo Local Falha
Solução:
- Verifique se a permissão de microfone está concedida
- Verifique Preferências do Sistema → Som → Entrada para seleção de microfone
- Tente um modelo diferente
- Reinicie o Vox
Qualidade de Transcrição Ruim
Soluções:
- Atualizar para um modelo maior: Tente Preciso ou Melhor
- Verificar qualidade do áudio: Fale claramente, reduza o ruído de fundo
- Adicionar palavras personalizadas: Use o recurso Dicionário
- Ativar Aprimoramento por IA: Pós-processe com IA para melhores resultados
Modelo Demora Muito Para Processar
Soluções:
- Fazer downgrade para um modelo menor: Tente Rápido ou Equilibrado
- Encurtar gravações: Divida ditados longos em partes menores
- Fechar outros aplicativos: Libere recursos de CPU
- Verificar atividade do sistema: Certifique-se de que seu computador não está sob carga pesada
Modelo Usando Muito CPU/Memória
Soluções:
- Mude para um modelo menor (Mais Rápido ou Rápido)
- Feche aplicativos em segundo plano
- Reduza a retenção de áudio para liberar recursos
- Considere atualizar seu hardware se precisar de modelos maiores
Tópicos Avançados
Arquitetura do Modelo
O Vox usa versões quantizadas de modelos Whisper otimizadas para:
- Inferência otimizada em todas as plataformas
- Menor pegada de memória
- Precisão mantida em relação aos modelos originais
- Aceleração do Neural Engine do Apple Silicon
Suporte a Idiomas
Todos os modelos Whisper suportam vários idiomas, incluindo:
- Inglês, Espanhol, Francês, Alemão, Italiano, Português
- Chinês, Japonês, Coreano
- E 90+ outros idiomas
Configure idiomas de fala em Configurações → Geral → Idiomas.
Modelos Personalizados
Atualmente, o Vox suporta apenas as cinco variantes Whisper integradas. O suporte a modelos personalizados pode ser adicionado em versões futuras.
Próximos Passos
- Ativar Aprimoramento por IA para melhor qualidade de transcrição
- Adicionar palavras personalizadas para melhorar a precisão de termos técnicos
- Configurar atalhos para gravação fácil
- Ajustar configurações do HUD para melhor feedback de gravação